Warning: Invalid argument supplied for foreach() in /home/xs642990/dark-pla.net/public_html/wp-content/plugins/bravo-neo/bravo-neo.php(12) : eval()'d code on line 647
さて、引き続きChatGPT関連で遊んでいきます。
先日は、ChatGPTの情報のソースをGoogleサーチにすることで、最新のニュースにも対応できるようにしました。
で、そのプログラムをしばらく使っていたのですが、長めの出力に難があることが多々。
例に挙げたような、「昨年末の紅白歌合戦の勝者はどっち?」みたいな問いならあれで十分なのです。
極論言えば、出力は「紅」か「白」の1文字で良いわけなので。
しかし、もう少し複雑な出力を求めるとちょっと難しくなってきました。
「室町時代の将軍と鎌倉公方の対立について」とかになると、とても一言では済みません。
そもそもグーグルに入力するキーワードも「鎌倉公方 将軍 対立」と3語入力になりそうですしね。
で、こういうことをすると前回のプログラムだとどうなるかというと…、落ちます。
トークン数の問題ですね。
どうもChatGPTのAPIで各モデルに設定された最大トークン数は、入出力の合計のようなのですね。
で、この手の複雑なキーワードになると、グーグルの中を隈なく検索してくれるのは良いのですが、得られたであろう回答を惜しみなくChatGPTのモデルに投げ込んでくれちゃうのか、入力の段階でほとんどのトークンを使ってしまいます。
gpt-3.5-turboだと入出力合計で最大4096トークンとのことですが、入力だけで4000を超えてきたりすると、文章で返答しなければならないケースには対応できないですね。
ではどうしたら良いか、ということで考えました。
基本戦略は「そんなに検索がんばらなくていいよ」ということなのですが。
具体的にはグーグルの検索結果での上位数サイトの情報だけをインプットに使って考えてみて、という指示をしました。
それから、一連の作業を検索と文章生成に分けると、もう一度文章を作り直してほしい、というときにまた検索から始めるのはコスト面からもよろしくない。
ということで、検索した結果は一旦自前で保存しておくことにしました。
方々を検索した結果、FAISSというものを使いvector indexを作成してそれを保存しておくというのが容量的にも良いらしい、ということに。
そして、適宜そのindexを読み込んで文章を生成させるという流れです。
実務的に想定されているのは、自前でなにかのサービスを提供している企業がQ&A集サイトを作るとか、カスタマーサポートをするときの支援とかで、自分たちで作ったマニュアルをこのインデックス化の対象とするといったような使い方です。
端からグーグルの検索に頼るようなやり方は邪道でしょうし、グーグルが検索結果を出しやすいような形式で訊ねている時点で過渡期的な感じもします。
自分で作っておいて何なのですが…。
自分が知りたいことと、自分が知りたいことを返してくれるであろう単語群を入力したときのグーグルでの検索結果はズレている可能性は常にあるので、そこで決め打ちして結果を作ってしまうと、ズレが増幅されるだけということもありそうだな、と。
検索意図そのものではなくそれを汲んだ単語群を入力している時点で、いくらその上位サイトの情報を取ってきたところで、危うさはあります。
これまでの我々も、ググるときに何度か言葉を変えて検索してみる、ということはやっているわけですからね。
そう考えると、ChatGPTはプロンプトが第一だ、なんてことが言われますけれども、それ自体はGoogle時代も同じですね。
結果は検索キーワード次第、というところがあったのですから。
というわけでプログラムは以下の通り。
1.与えられた単語群の検索結果から、その上位nサイトのURLを返すプログラム。
2.そこで得られた上位nサイトの情報を取ってきてインデックス化するプログラム。
3.そのインデックス情報を使って、文章を生成するプログラム。
自分の知りたいことはグーグルではどのような単語群を入力したら得られるのか、ということを自分の頭で考えて最初のプログラムを走らせているので、上述のように、作成したインデックスの持つ情報が、本来自分の知りたいこととズレている可能性があります。
そこで少し本末転倒気味ではあるのですが、与えられた単語群で得られるグーグル検索結果の上位サイトの内容から、グーグルの考える検索者の検索意図はこれではないか、ということをChatGPTに類推させ、そしてその検索意図に対する回答をchatGPTに出させる、というやり方を取ってみました。
まあ、こうすることで、文章が生成できない、という事態にはなりません。
自分の知りたいこととはズレる可能性はありますが、生成された文章自体は中身が皆無ということはなくなります。
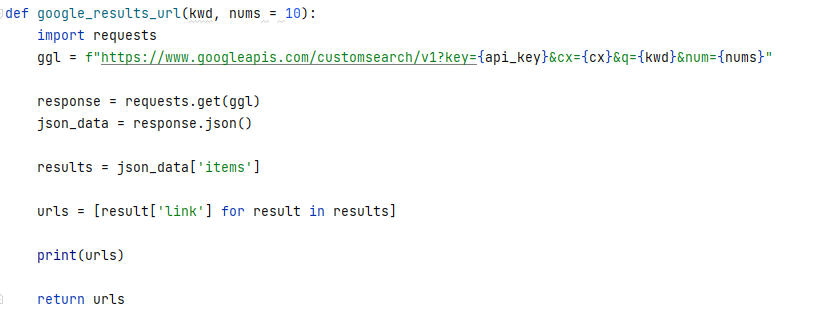
1.与えられた単語群の検索結果から、その上位nサイトのURLを返すプログラム。
def google_results_url(kwd, nums = 10):
import requests
ggl = f"https://www.googleapis.com/customsearch/v1?key={api_key}&cx={cx}&q={kwd}&num={nums}"
response = requests.get(ggl)
json_data = response.json()
results = json_data['items']
urls = [result['link'] for result in results]
print(urls)
return urls
2.そこで得られた上位nサイトの情報を取ってきてインデックス化するプログラム。
def make_index_faiss_json(urls):
documents = SimpleWebPageReader().load_data(urls)
service_context = ServiceContext.from_defaults(llm_predictor=LLMPredictor(llm=ChatOpenAI(model_name="gpt-3.5-turbo")))
d = 1536
# コサイン類似度
faiss_index = faiss.IndexFlatIP(d)
# APIを実行しFaissのベクター検索ができるようにする
index = GPTFaissIndex.from_documents(documents,
faiss_index=faiss_index,
service_context=service_context
)
# save index to disk
index.save_to_disk(
CE.downfolder + 'index_faiss_1.json',
faiss_index_save_path=CE.downfolder + "index_faiss_core_1.index"
)
3.そのインデックス情報を使って、文章を生成するプログラム。
def mdl_article_index(id_omod):
index = faiss.read_index(CE.faissfolder + 'model_faiss_core_1.index')
print('検索意図の策定')
prompt = PromptTemplate(template="""Use the context below: Context: {context}"""
, input_variables=["context"])
system_message_prompt = SystemMessagePromptTemplate(prompt=prompt)
# ユーザーからの入力
human_template = """Write the search intent of the person who entered keywords below into the search engine in Japanese.
Keywords:{search_kwd}
Intention(in Japanese):"""
# User role のテンプレートに
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template, input_variables=["search_kwd"])
# テンプレートをまとめる
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# LLM
llm = ChatOpenAI(temperature=0.1)
chain_1 = LLMChain(llm=llm, prompt=chat_prompt, output_key="intention")
print('回答作成')
prompt = PromptTemplate(template="""Use the context below: Context: {context}"""
, input_variables=["context"])
system_message_prompt = SystemMessagePromptTemplate(prompt=prompt)
# ユーザーからの入力
human_template = """Write an answer to the following search intent in Japanese.
intention:{intention}
article(in Japanese):"""
# User role のテンプレートに
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template, input_variables=["intention", "keyword_incl", "keyword_excl", "model_description"])
# 先に定義したテンプレートをまとめて、ひとつのChatTemplateに
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# LLM
llm = ChatOpenAI(temperature=0.1)
chain_2 = LLMChain(llm=llm, prompt=chat_prompt, output_key="article")
print('シーケンシャルにして実行')
overall_chain = SequentialChain(
chains=[chain_1, chain_2],
input_variables=["context", "search_kwd"],
output_variables=["intention", "article"],
verbose=True
)
# SequentialChainの実行
response = overall_chain({"context": index, "search_kwd": srch_kwd})
print(str(response))
これで途中でトークン数を理由にプログラムが落ちることはめっきりなくなりました。